In any situation where one piece of work has to happen before another, there’s a dependency. Sometimes they’re avoidable, other times they’re inevitable, occasionally they’re even desirable.
Dependencies between tasks in Jira can be intra-project or cross-project and can happen for all sorts of reasons. Regardless of why or how they happen, one thing always results: your system and processes become more complex.
This is where the importance of Jira dependency management comes in. An essential skill for any leader, managing Jira dependencies so as to prevent them from becoming bottlenecks is vital to ensure a smooth workflow and deliver value on time.
In this ultimate guide, we’ll explore:
- types of dependencies and how to add a dependency in Jira
- ways to visualize dependencies through a Jira dependency graph or map
- limitations of managing dependencies in standard and premium Jira
- how to do Jira dependency management more effectively using Dependency Mapper for Jira
But first things first: should we even be talking about this?
Should I even have dependencies in Jira?
It’s a reasonable question, particularly as Jira is an agile tool, and some agile purists will say that dependencies shouldn’t exist.
After all, shouldn’t agile teams be self-sufficient, self-sustaining and cross-functional, delivering value from end to end? And don’t dependencies lead to idle time, i.e. waste? Ergo, they reduce agility? There are scaled agile professionals who say that the first rule of scaling up your agile practices is don’t have dependencies.
However, as we explored in a recent interview looking at dependencies in the Scaled Agile Framework (SAFe), trying to eliminate dependencies altogether is unrealistic and in some cases undesirable.
Yes, some dependencies are the result of a poor or overly complex org chart, i.e. too many cooks. These are the types of dependencies that teams should work to eliminate.
At the same time, value can be gained from having dependencies in terms of collaborating, sharing knowledge and expertise, and building relationships with other teams across an organization.
Moreover, teams will deliberately create certain dependencies to reduce risk. For example, one team member writes an article and another reviews and edits it. Or one team member develops a feature and a different one tests it. There’s an inherent risk if you only have one person responsible for both the “doing” and the “checking”, so teams add dependencies to mitigate that risk.
What is Jira dependency management and why is it necessary?
The fact that some dependencies are inevitable or even desirable only underscores the importance of Jira dependency management; teams need to see and understand their dependencies to know what to do about them.
Jira dependency management involves visualizing, tracking, and resolving the dependencies that exist between Jira issues and projects. More specifically it involves:
- Understanding the different types of dependencies that exist in Jira, e.g. “blocks”, “relates to”, “causes”
- Using dependency mapping in Jira to gain a better understanding of the dependencies between projects, processes, and people
- Identifying which dependencies are necessary versus which are not and should be eliminated
- Analyzing necessary dependencies and predicting how they will affect delivery
- Ensuring plans in Jira are feasible, taking account of necessary dependencies
- Keeping on top of deliverables that other teams are waiting for
If you don’t actively manage your Jira dependencies, things can go sideways fast. Imagine a house renovation where building work can’t be done on schedule because the plumbing isn’t finished. This adds extra costs and what if the people who need to be rebooked aren’t available?
Dependency management in Jira is a proactive process that stops this snowball effect of increasing costs and missed deadlines that can derail projects. It can also reduce complexity, improve the flow of work, increase cycle and lead times, and facilitate better cross-project planning.
How to add a dependency in Jira
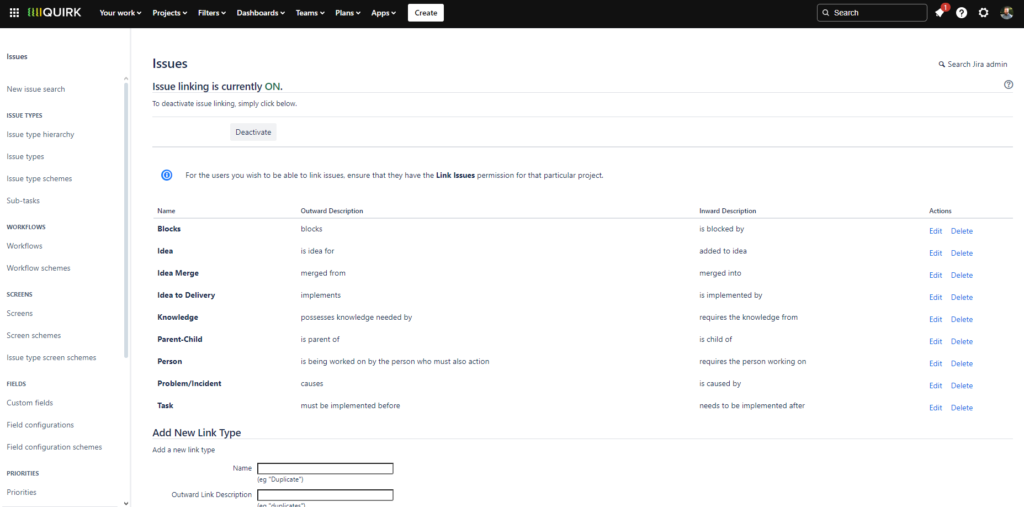
You can add a dependency in Jira by using issue links. Link Jira issues from the same or different projects to indicate that one task depends on another. Different issue link types are available to accurately represent the nature of the dependency, i.e. the way one task affects another.
Jira comes with the following issue link types, which can be deleted or changed by a Jira admin if they are not necessary or appropriate:
-
- blocks/is blocked by
-
- causes/is caused by
-
- implements/is implemented by
-
- relates to
-
- is idea for
-
- added to idea
-
- merged into/merged from
-
- clones/is cloned by
-
- duplicates/is duplicated by
-
- reviews/is reviewed by
The most classic dependency scenario would utilize the link type “blocks/is blocked by”, which means that one task cannot start or finish until the other has started or finished. Issues linked in this way dictate the necessary order of work for the purposes of building a schedule.
That said, you may think that the word “blocks” suggests that there’s already a bottleneck, so you could change this link type to the more positive “requires/is required by”.
Software development and IT service management (ITSM) teams are likely to use “causes/is caused by” to indicate when one bug or problem is causing another. Those same teams might use “implements/is implemented by” to connect user stories with development tasks.
Why good Jira dependency management starts with issue links
The first step towards good dependency management in Jira is making sure your instance has the most sensible issue link types and that your users understand what they are and when to use them.
Unfortunately, some of the out-of-the-box issue link types may or may not even indicate dependencies. If, for example, one issue “relates to” another, both issues could still be capable of being completed independently. This is why it is important to make sure your users understand what your link types mean, and that you only use link types like “relates to” where the connection is not a dependency.
Beware of having too many issue link types, duplicate link types, or vague/unclear link types where it isn’t at all obvious how the issue is dependent on another. In all cases you run the risk of teams linking issues in ways that aren’t an accurate reflection of what the dependency is. This makes it harder to manage and resolve those dependencies at a later stage.
How to make sure your Jira issue linking helps with dependency management
Most organizations should be able to consolidate their Jira dependencies into three main categories:
-
- knowledge – when a piece of information is required for a task to progress
-
- process – when a task must be completed before another can proceed, which affects overall project progress
-
- resource – when another entity (human or technical) is needed for a task to progress
If you think of your dependencies in these terms, you should then be able to define better issue link types to match.
For example, an issue link type for a knowledge dependency could be “provides knowledge to/requires knowledge from”.
For a process dependency, you could have “must be completed before/must be completed after”. It’s similar to “blocks/is blocked by” but actually describes the sequence of work and is therefore clearer.
And for a resource dependency, your link type could be “allocates resources to/requires resources from”.
Options for visualizing dependencies in Jira
Visualization is at the very heart of Jira dependency management. Visualizing dependencies helps teams see where their dependencies are, identify potential patterns of dependencies, and understand how work correlates between teams and teams of teams. Once you’re on top of what your dependencies are, you can plan your sequence of work, resolve bottlenecks, and predict the impact of dependencies on delivery.
Let’s look at the ways in which you can visualize dependencies in Jira.
Visualizing dependencies on your Jira board
Once you’ve created your issue links, you can choose to show linked issues on your Jira board using view settings. Once enabled, issue links are highlighted on the relevant issues’ cards. However, all this does is add the issue key of the linked task under the issue name, which hardly counts as visualization of your dependencies.
A better option would be to use Jira Query Language (JQL) to make issue cards a specific color if they have a certain link type, e.g. making “is blocked by” issues red. This enables teams to start doing some dependency management on their agile board.
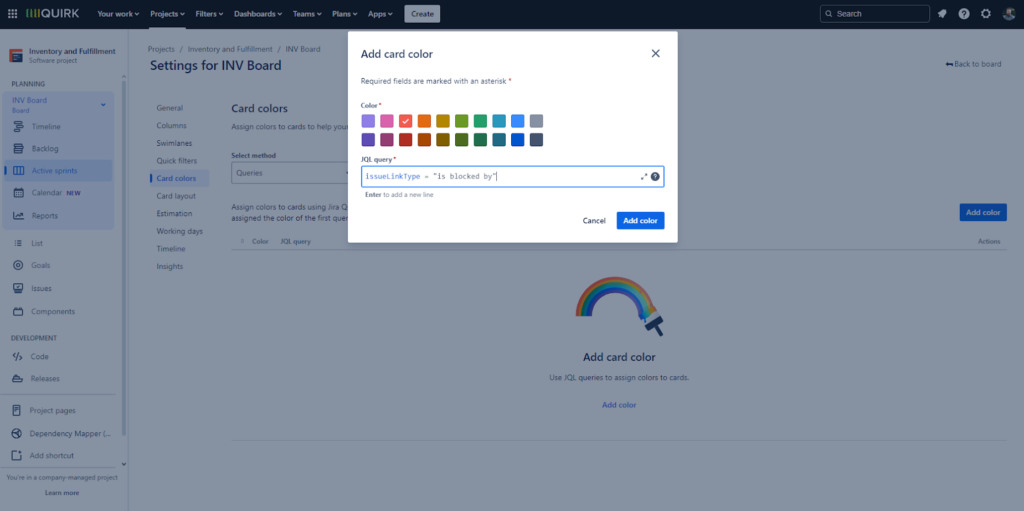
However, these board visualization options are limited and only assist with dependency management on a very small scale, i.e. you only have a handful of intra-project dependencies and you’re happy to manage them within your team. Even then, you’d probably want to stick the dependencies into a spreadsheet for a clearer overview.
Dependency views in Jira Plans
Jira Premium, which gives you access to Jira Plans (formerly known as Advanced Roadmaps), has more options for visualizing and managing dependencies. Here, managing dependencies happens in the course of building an all-encompassing plan or roadmap that combines issues from different boards, projects, and filters. In other words, dependencies are just part of a much larger whole.
In Plans, you can view dependencies on your plan and see how they impact your timeline, or add new dependencies and factor them in. Dependencies appear by default as lines between issues, with risky dependencies showing as red lines (such as blocking issues planned after the issues they’re blocking). You can choose to display dependencies as badges instead if your roadmap starts to get messy because of all the lines. You can also filter for a specific dependency when you want to investigate them further.
However, Jira Plans doesn’t automatically reflect the issue link types you’re using in your Jira; rather, it defaults to “blocks/is blocked by” for all dependencies. A Jira admin has to go in and add other link types. If this doesn’t happen, it means that you’re not capturing the real nature of your dependencies in your plan.
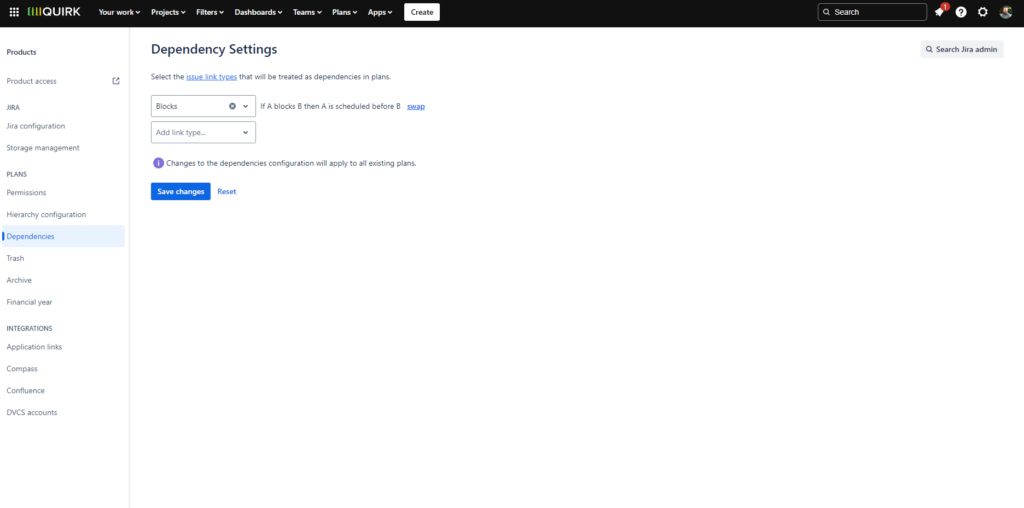
Dependency mapping in Jira Plans
When you have a larger number of dependencies involving multiple teams across the organization, you need to start looking at ways of creating a Jira dependency graph or map.
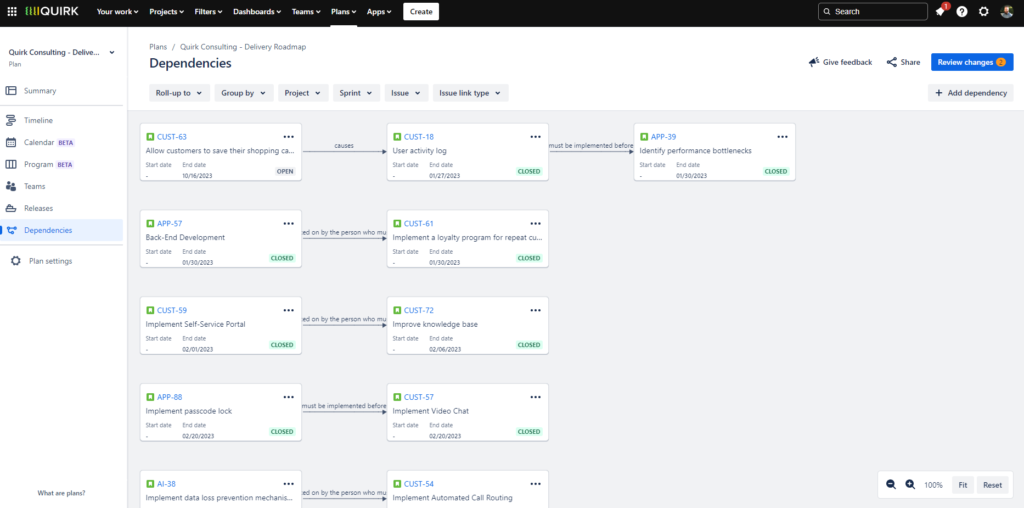
In Jira Plans, there is a single dependency graph available in the dependencies report tab, which lets you map out all the related issues in a plan. This displays issues as tiles with arrows to illustrate their relationships to others.
Unfortunately, there’s very little you can do with this report. There are no customization options and, although you can roll up the dependency map to the epic and initiative levels, there’s no way of grouping dependencies or seeing total numbers of dependencies at a glance. The limited dependency visualization options in Jira Plans are not enough for most teams or their stakeholders.
Dependency mapping in Dependency Mapper for Jira
Dependency Mapper for Jira is an Atlassian Marketplace app that automatically visualizes the relationships between Jira issues and projects based on the issue link types you’re already using. It offers a detailed or bird’s eye view of your dependencies in more than 20 dependency graphs, maps, and other visualizations designed to suit different stakeholders.
With Dependency Mapper, you can easily see what is being delivered when, with real-time dependency and team impact data. It’s much easier for stakeholders to understand the sequence and progress of work and make decisions on it. This makes it an excellent tool for planning, particularly big room or program increment (PI) planning involving multiple teams.
Here are some of the visualizations available and what you can do with them.
Dependency matrix
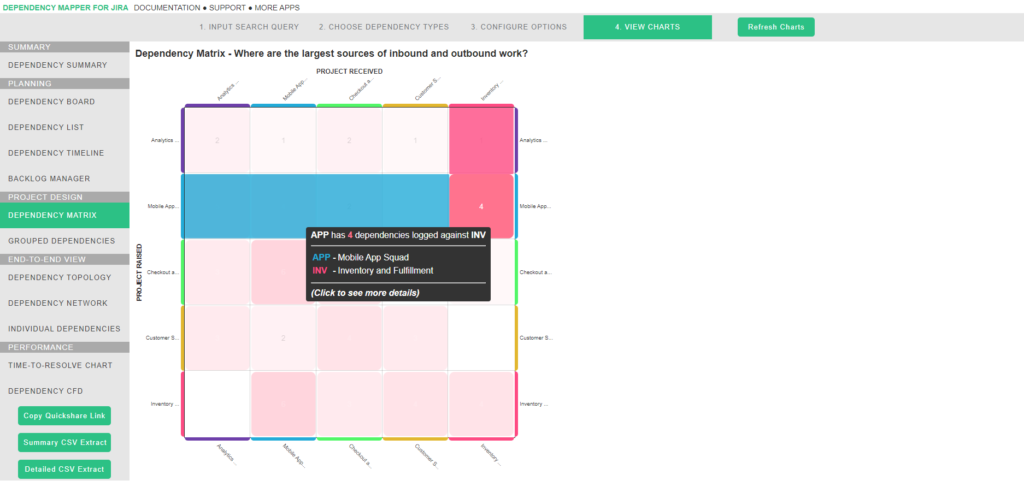
This shows all raised and received dependencies in a table format, with each cell representing the number of dependencies between two projects. This can be useful for identifying dependency ‘hot spots’ within a team of teams. If two particular teams have an abnormally high number of dependencies tagged against each other, it could be an opportunity to rethink how those teams are configured.
Grouped dependencies chart
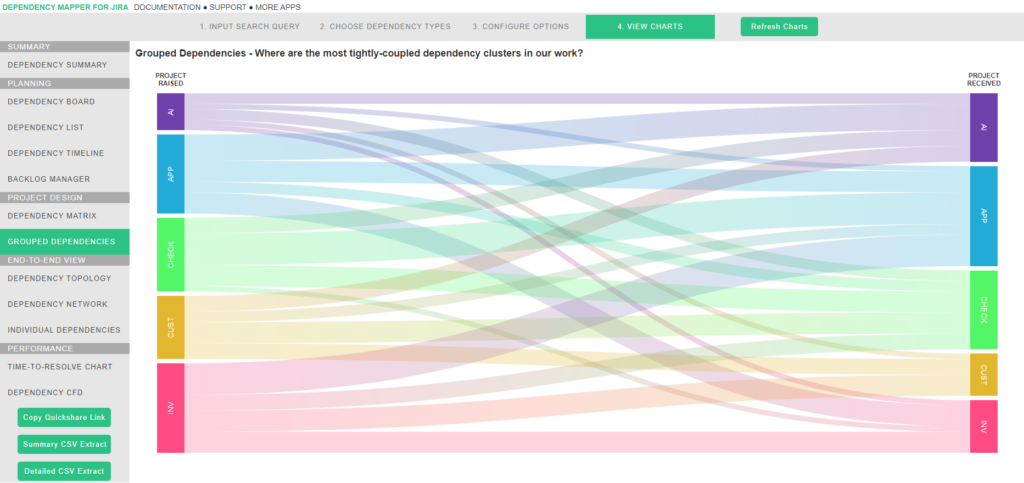
This Sankey diagram shows the volume of dependencies raised by each team on the left, and the volume of of received dependencies on the right. We can use this to analyse where there are abnormally high inbound or outbound dependencies for particular teams, and whether it makes sense considering the type of team they are.
For example, an internal service desk would expect a high volume of inbound dependencies, but it would be strange if they had a high number of outbound. Conversely, a feature team with a high volume of either inbound or outbound dependencies would indicate they are not properly equipped to deliver value independently as was intended.
Dependency topology chart
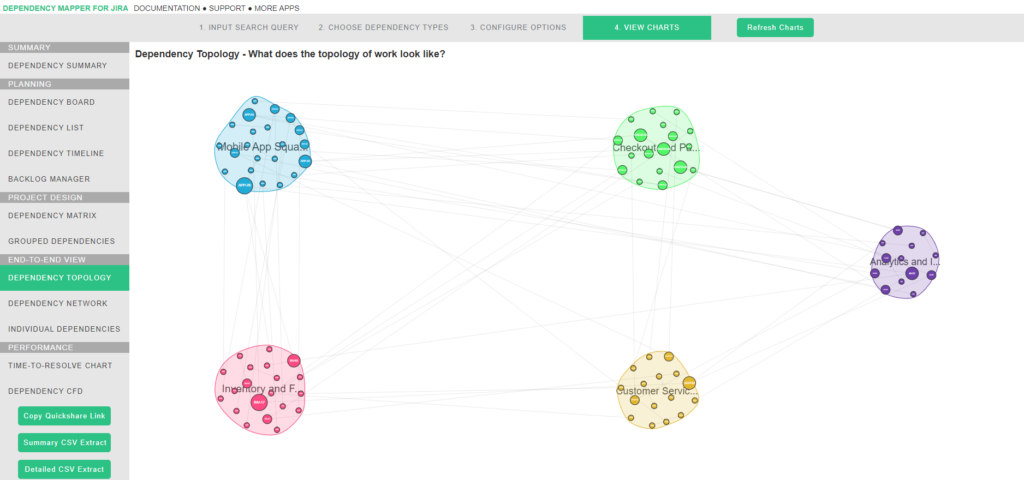
This shows all individual dependencies as circular nodes, grouped together based on project, epic, fix version or sprint. This shows us two things:
-
- The larger nodes have more dependencies, so we can identify outliers or otherwise critical dependencies easily here.
-
- The lines between each group can be an analogy for the traffic highways between each town. More lines = more traffic = more complexity.
Dependency network chart
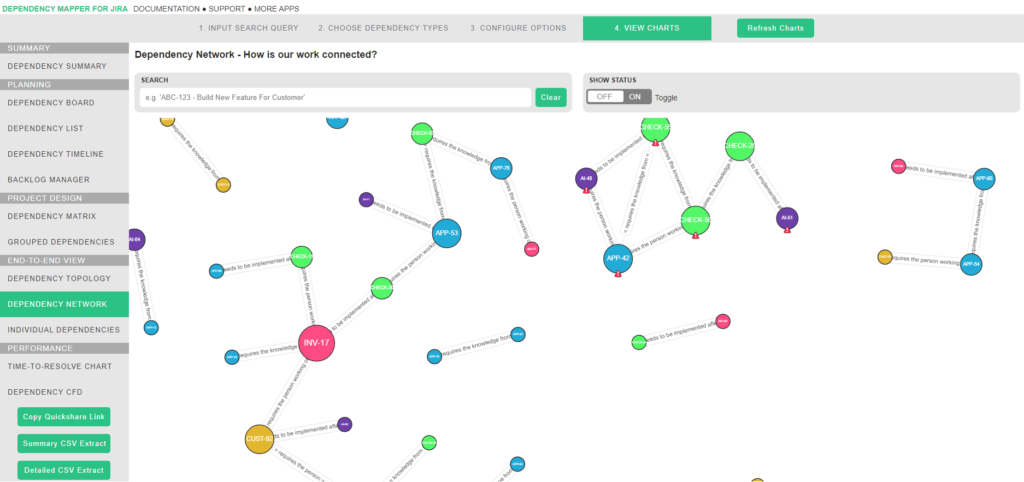
The other charts focus on the direct relationship between two things i.e. A depends on B. But more often than not, the work is more complex than that, i.e. A depends on B, which depends on C, D, E etc.
This chart shows the dependency ‘chain’ of those complex relationships, which often forms a spiderweb-like view in Jira.
Dependency summary dashboard
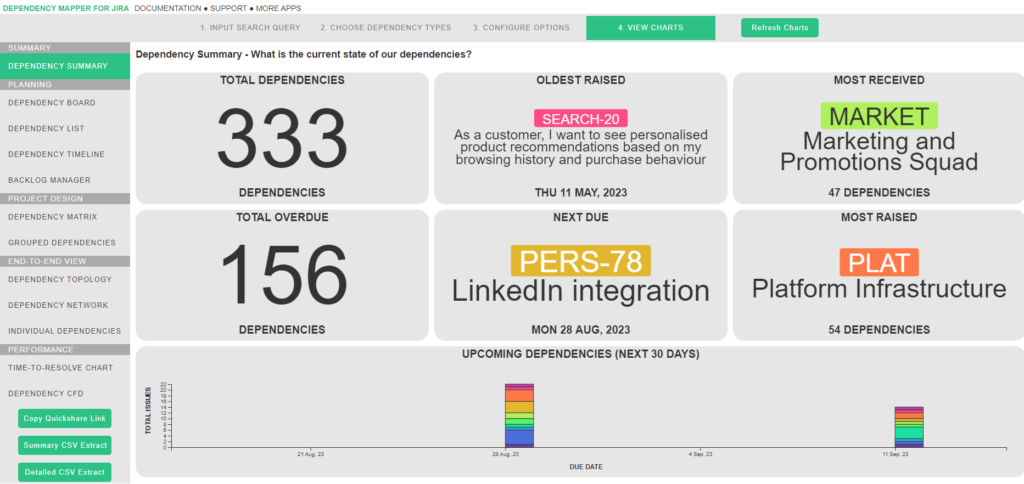
This summarizes total dependencies, dependencies with the next closest due date, projects and epics with the highest number of dependencies, and more. It’s designed to provide at-a-glance insights for everyday dependency management, so that teams can know what’s on the short-term horizon and what their focus should be.
The documentation for Dependency Mapper for Jira has more information about the different Jira dependency graphs and charts available.
Also, our blog offers a more a detailed breakdown of how Jira Plans and Dependency Mapper for Jira compare, so that you can decide which tool is best for your organization.
To summarize (TL;DR)
-
- Jira dependency management is a proactive process that reduces complexity, improves the flow of work, and stops projects from being derailed by extra costs and missed deadlines.
-
- Dependencies in Jira rely on issue links. Jira comes with a whole bunch of issue link types, but some aren’t that helpful and could confuse your teams. You’d be better off making your own and naming them something that accurately describes what the dependencies are.
-
- In Jira Standard, you can see issue links on your agile board, but the visualization options are minimal. It’s fine if you only have a few dependencies to manage and they’re intra-project rather than cross-project dependencies. Otherwise, it’s not enough.
-
- In Jira Premium, you can visualize dependencies when working with Jira Plans (formerly Advanced Roadmaps). However, dependencies in Jira Plans are part of a larger whole (your roadmap) and therefore there isn’t much scope for dependency mapping and visualization.
- Dependency Mapper for Jira is an Atlassian Marketplace add-on focused solely on the dependencies use case. As a result, it offers all the dependency graphs, maps, and visualizations you could need to be able to do effective dependency management in Jira.




